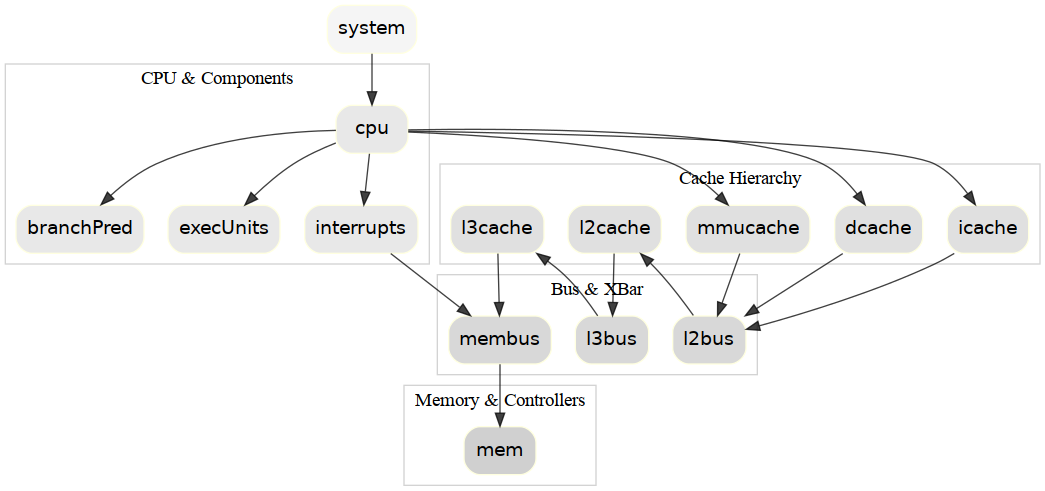
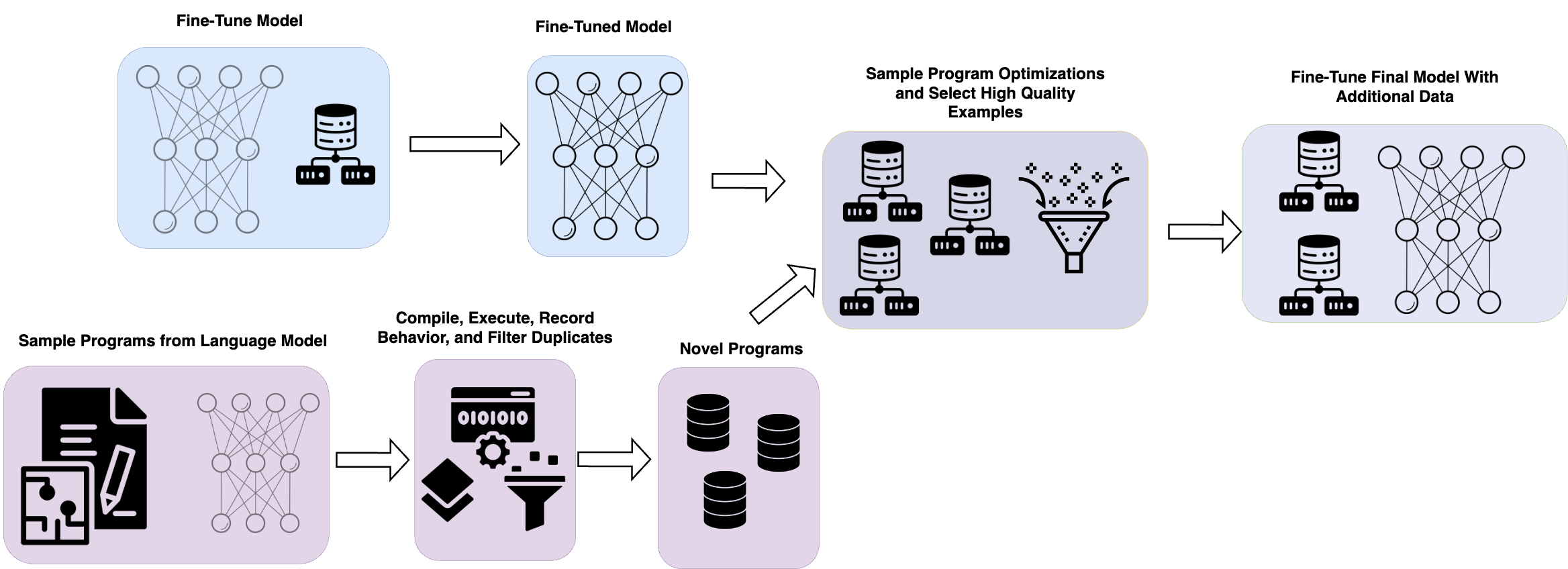
We perform extensive experiments to evaluate and improve Large Language Models (LLMs) for program optimization.
We built a custom evaluation framework that benchmarks program execution time in a highly-reliable manner. When measuring average program speedup,
we obtained models capable of outperforming edits made during competitive programming contests. We also obtain a model that is able to set a
higher upper-limit for speedup than the fastest submissions in the dataset.